



Having a clear and organized system for metrics is essential when you need answers fast—especially during incidents. Imagine you’re dealing with a system issue or a sudden spike in traffic. These are the kinds of high-pressure situations we call 'incidents.'
During these times, you need to get information quickly to understand what’s going wrong and how to fix it. That’s where having a well-organized system of metrics comes in.
When metrics are structured thoughtfully, it’s like having a well-organized toolbox. You can find the right tool (or piece of information) fast. For example, if your application is running slow, you can instantly check specific parts of your system to pinpoint the problem—whether it’s a server issue, network lag, or something else. Having metrics arranged like a tree, with clear categories and relationships, you can drill down into the details and see exactly what’s causing the problem.
You don’t have time to sift through a jumble of data in a crisis. You need to see patterns and get answers right away. That’s why structuring metrics well isn’t just a nice to have; it’s crucial for quickly diagnosing and resolving issues. This post will show you how to set up your metrics so that when an incident strikes, you’re ready to tackle it head-on with clear, actionable insights."
Many of these concepts will be familiar as they are first-class ideas of cloud-native monitoring solutions such as Prometheus and DogStatsD.
Metric Spaces
Think of metric spaces as the areas where your metrics are kept. These are usually organized within a database or account

But it’s not just about storing metrics—how you name and organize them can make a big difference. In the example shown, the metric space doesn’t have any specific organization. Each metric is just out there on its own, with no links or structure connecting them. This means you have to look at each metric individually. For instance, to find out the number of HTTP requests for a service, you need to check a specific metric like service_N_http_requests_total.

Now, imagine you want to see the total number of requests across all services. In the current setup, if a new service is added, like service_3, the total request count won’t update automatically. You’d need to manually include service_3_http_requests_total in the total. Without a proper structure, you’re left doing extra work to keep everything accurate.
This can be seen in the chart below:

Metric Trees
Instead of having a random, unorganized space for your metrics, you can use a clear, structured approach where metrics are organized like a tree. just like the structure below:

In tools like Prometheus and Datadog, this organization is done using labels and tags. With tags, when you add a new service, it automatically fits into the existing structure, keeping everything connected and up-to-date.
For example, in Prometheus, you can easily see the rate of requests per second across all services.

The structured setup allows you to dynamically calculate totals, so when you look at the main metric, it automatically includes data from all individual services. This means you don’t have to manually update totals—everything adjusts itself as new services are added.
Defining a metric based on its sub-metrics
Think of defining a metric in terms of its 'sub-metric' or ‘children’ like organizing data in a family tree. Each branch (or 'dimension') of the tree, such as the 'service' label, holds the specific request rate for that part. With this organized structure, you can not only see the overall rate but also look at the rate for each service.

By setting up your metrics this way, you get a clear picture of how the different parts contribute to the whole.
For example, you can break down data to see details like the p99 latency (the time taken for 99% of requests) for different types of servers or deployments.
Increasingly Specific — Subsets of data
This organized approach also helps you focus on specific parts of the data. For instance, you can answer questions like: What’s the p99 latency for successful requests on canary deployment machines?

While the tree shows the general idea, it doesn’t always reflect exactly how metrics are stored. However, with a well-defined structure, you can easily expand and dive deeper into the data, like checking p99 latency for each machine in a canary deployment.

Combined with the technique above this can get more specific along any dimension of the metric: What’s the p99 latency on all successful http requests for canary deploy machines per machine?

In Prometheus, you can use this structured approach to break down metrics further by details like machine_id.

This way, the main metric can be dynamically updated to include specific information about each machine.
Ratios Rule
Using ratios is a powerful way to connect and compare data, even in a space that isn't well-organized. This technique is crucial for calculating things like availability and error rates, which are key in SRE (Site Reliability Engineering) practices popularized by Google. Ratios let you link different metrics together, giving structure to your data.
For example, if an application can have different outcomes, like 'cache hit' or 'cache miss,' you can use ratios to see how often each happens. To find the cache hit ratio, you need to organize the data so you can calculate it

In the graph below, you can see the rate of cache hits versus misses. With around 160 requests per second,
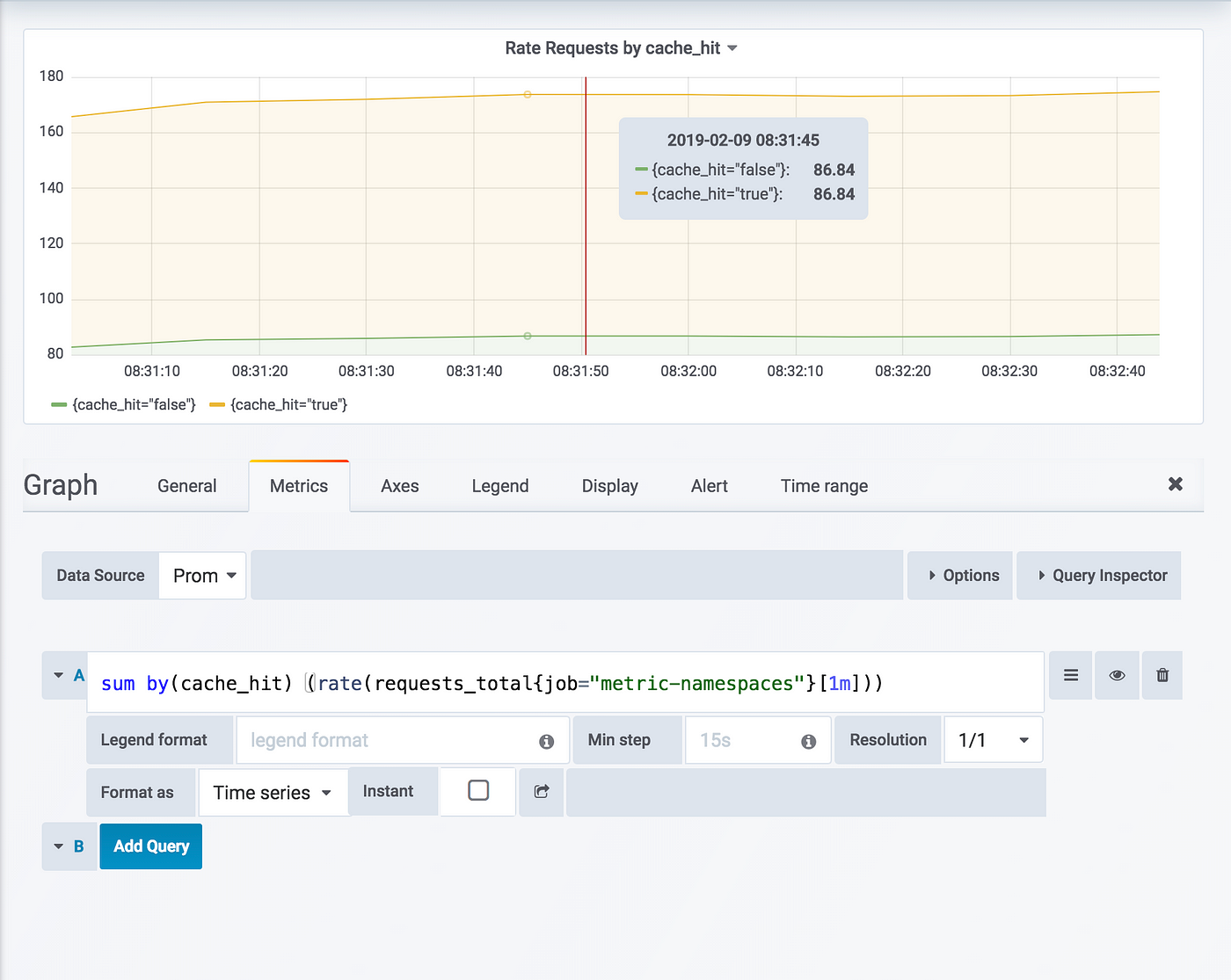
The chart shows that 50% of the requests are cache hits.

This method creates a logical connection between metrics, even though it's not always a direct or fixed link. In tools like Datadog and Prometheus, this connection is often shown as a simple mathematical operation. Because this calculation happens when you query the data, you can relate any two metrics to each other.
Questions
A lot of times, It all comes down to the questions you ask. To get the most out of your data, think about what you want to know and make sure your metrics can answer those questions.
For instance, if your current setup can’t tell you 'How many requests per second are all instances handling?', a well-structured namespace tree can.
Another approach is to organize metrics by the service using them, rather than by the client library. This way, you can easily answer questions like, 'What’s the total number of requests from all clients?'
Here are some general questions that align with Google’s four golden signals, starting broad and then drilling down:
How many requests are all clients making in total?
How many requests is each client making?
How many requests is each client making per machine?
What’s the rate of successful requests per machine and per RPC?
You can use the same method to explore latencies, error rates, and resource usage. This approach helps you get clear, actionable insights from your data.
##
To get the best results from your metrics, it's useful to start with general metrics and then add tags or labels to make them more detailed. Both Datadog and Prometheus suggest this approach for optimal querying and storage.
Begin with a broad, general metric at the top level. From there, add tags or labels to refine the data and drill down into specific details. This way, you can start with a big-picture view and then focus on particular segments as needed.
For example, you might start with a general metric for 'request rate' and then add tags like 'service type' or 'region' to get more specific insights. This method allows you to maintain a global overview while also being able to dive into finer details.
Be mindful of cardinality
Be mindful of cardinality when working with metrics. Both Datadog and Prometheus recommend keeping it under control. Here’s why:
In Prometheus, each combination of labels creates a new time series, which can use up RAM, CPU, disk space, and network bandwidth. While this overhead is usually small, it can quickly add up if you have many metrics and labels across numerous servers.
As a rule of thumb, try to keep the number of unique combinations (cardinality) for each metric below 10. For metrics that need more, aim for just a few labels across your entire system. Most of your metrics should not use any labels.
If you have a metric with over 100 unique combinations, or if it might grow that large, consider other options. You might reduce the number of dimensions or move the analysis to a different system designed for handling large datasets.
For instance, consider node_exporter, which tracks metrics for each filesystem. With 10,000 nodes, you might end up with 100,000 time series for just one metric. Adding more details, like quotas per user, could push this into the millions, which is too much for Prometheus to handle efficiently.
If you’re unsure, start with metrics that have no labels and add them only when necessary. For user-level observability, distributed tracing might be a better choice, as it has its own set of best practices and is designed to handle complex data in different ways.